

第二部分:自动化安全运营中心(SOC)世界之旅

通过
8分钟阅读

安全运营团队一直致力于关注两件主要事情:1。2.真正的网络安全威胁(也称为“真正警报”);减少响应时间,特别是当您有许多不同的源要监视时。然而,在现实中,我们处理数百个安全警报在日常生活中,很多都是误报,浪费了我们宝贵的时间。这就是事件响应/安全自动化成为一种需求的地方,而不是最好的地方。
那么,这篇博文是写给谁的呢?
- 如果你花很多时间在调查步骤和过程单调找到你自己跳在多个平台之间获得初步裁决-这是给你的。也就是扩大分诊范围.
- 如果你收到了很多信息不足的提醒快速的决定和衡量潜在风险-这是给你的。又名浓缩.
- 如果你的观点/人纠正风险并建议行动是在不同的时区这只会增加分辨率和响应时间,这是给你的。AKA升级和响应.
本博客将解释我们的网络安全事件响应团队(CSIRT)团队如何设计和选择我们今天拥有的事件响应自动化解决方案。希望分享我们的用例可以为您和您的组织提供额外的指导。这是三篇博文的第二部分,包括:安全监视(又名SIEM),自动化(又名SOAR)和机器人(又名聊天机器人)。
首先,让我们回顾一下我们的团队。
JFrog的安全工程师
JFrog Security - CSO办公室专注于保护客户数据,确保云基础设施的安全性,提供最高的产品和应用安全标准,并应对新出现的安全威胁。了解更多关于JFrog保安>
挑战:首先,让我们面对现实
在大多数常见的组织中,与每天接收到的警报数量相比,安全操作团队的人数可能要多一些。
让我们假设一个例子,我们的团队中有5个人,每个人每天最多可以处理7-10张票。如果每个罚单需要15-20分钟才能得到初步裁决,这将增加大约半天的团队工作,您仍然需要处理补救步骤。但是,现实情况是,您的组织很可能需要处理比这更多的警报,并且会发生以下两种情况之一:
- 好情况-你的团队将进行彻底的分类和调查,但很快就会开始“缓存”警报,永远不会设法处理所有事情。
- 糟糕的情况-质量下降,取而代之的是“首要任务是关闭门票”。
在这两种情况下,你的团队可能会进入“警惕疲劳”区域,浪费时间和动力。
怎么解呢?
我们可以将其缩小到3个选项:
- 雇佣更多的人-高度影响预算和运营(招聘,指导,管理)。
- 处理更少的警报-影响您保护组织的能力。
- 启用安全自动化-覆盖所有安全警报,没有人为干预,也就是使用机器人
让我们深入了解如何使用Slack聊天机器人创建自动安全警报解决方案。
准备,保持专注
没有计划,你会迷失方向。

我们首先手工调查我们的每一个安全事件类型并为每一种情况制定了专门的剧本(调查过程和应对计划)。这有助于我们在安全自动化集成类型(例如AWS / Gsuite / Slack /等)和剧本操作中实现数据准确性。
接下来,我们检查警报度量和统计在我们的安全运营中心(SOC)中识别出最嘈杂的警报(不一定是关键的),这些警报必须成为自动化的第一个候选。
最后,我们选择了最多的高效、便捷的沟通渠道为我们的组织(Slack)提供最大的覆盖范围,减少响应时间并吸引相关的利益相关者。
*重要说明:从最耗时的安全警报开始,让您的团队在关键警报上花费更多时间。
技术很重要,明智地选择
以下是我们在选择安全/事件响应自动化技术时使用的4条准则:
- 识别正确的平台
我们专注于设计事件响应(IR)自动化剧本,而不是开发新的平台集成。我们确保任何额外的定制都是直接且易于实现的。 - 错误处理
提前一步考虑,剧本就像微服务,它们一起作为一个完整的系统发挥作用。我们依靠自动调查和响应过程,使我们能够实时监控错误。 - 团队协作
我们意识到在团队成员之间分享知识是无价的。安全威胁反复发生。我们确定了他们的模式和危害指标(IOC),使我们能够采取先进的响应行动。
就像研发团队一样,共同开发是成功的关键——你不想成为自己开发的剧本的焦点或瓶颈。开发和生产需要版本控制和分离的环境。 - 事件管理平台
我们想要一个单一的事件管理平台,包括:事件类型、事件布局、事件所有者、事件持续时间、事件仪表板等对我们来说非常重要的功能。
开发我们的自动化剧本
第一步:调查-扩大我们的分类
处理无信息的警报意味着有很多悬而未决的问题,所有这些回答问题的重复任务都是浪费时间,会产生两个(坏)影响:削弱分析人员的能力,并为攻击者赢得更多时间。
我们开发了一个自动化的过程来调查和丰富原始数据登录少于5分钟并将其直接发送到Slack警报通道。这最大限度地减少了我们的分诊时间,以便在一个可访问的通信渠道获得初步裁决。我们可以看到原始数据日志和增强的bot警报之间的区别。
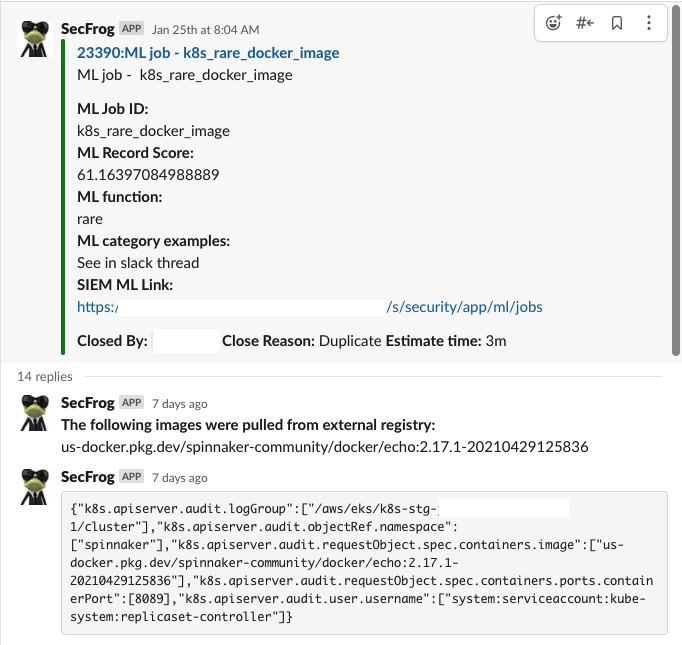
步骤2:事件状态-减少误报并开始做出决定
我们知道我们的时间非常宝贵,所以我们决定只把时间花在“真阳性“网络安全威胁。我们不想处理不再存在的威胁,甚至从一开始就不存在的威胁。
我们完全自动化了这个过程回答问题然后为我们需要做的每个决定建立分支来判断是否为假阳性。
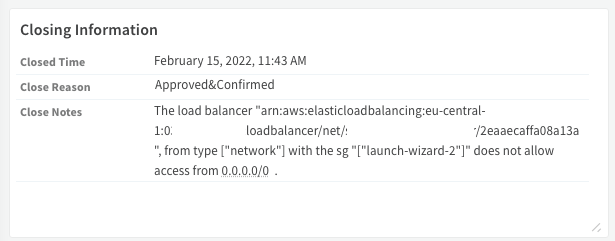
第三步:升级——关键是时机!
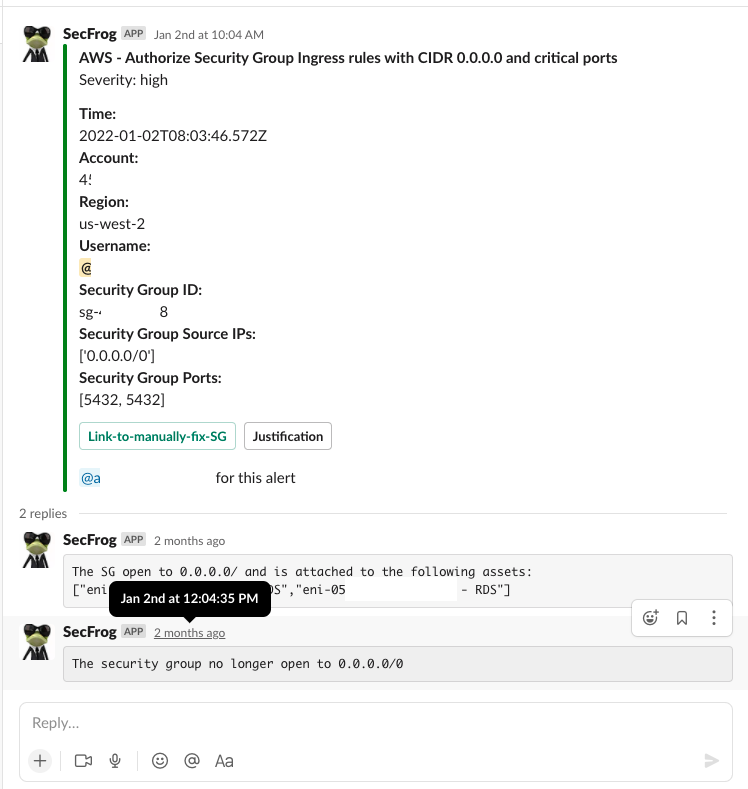
通过向共享的Slack频道直接发送信息和交互式警报,我们能够让我们的用户(在我们的案例中是组织中的其他团队)成为事件所有者。警报包括上述自动调查步骤产生的所有相关细节和结论,帮助事件所有者做出响应独立快速.
通过将事件详细信息直接发送给所有者,我们缩短了风险生命周期(达到2小时补救SLA)。
通过这样做,我们也实现了员工意识!我们提高了员工对网络安全威胁的意识。实时警报有助于将他们最近所做的事情与所提出的安全问题联系起来。
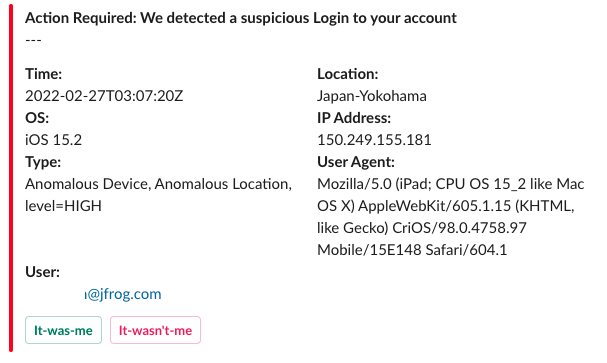
步骤4:自动修复——毫不犹豫
最后,基于用户的响应输入,我们为用户构建了自动修复步骤。换句话说,用户将获得自动警报,对其作出响应,并从系统触发自动修复操作。
实质上,攻击者失去了他们的优势。
最后的架构
总结一下,这是我们最终的自动化架构,结合我们的以前的安全监控解决方案架构和我们的IR自动化架构,创建端到端自动化SOC。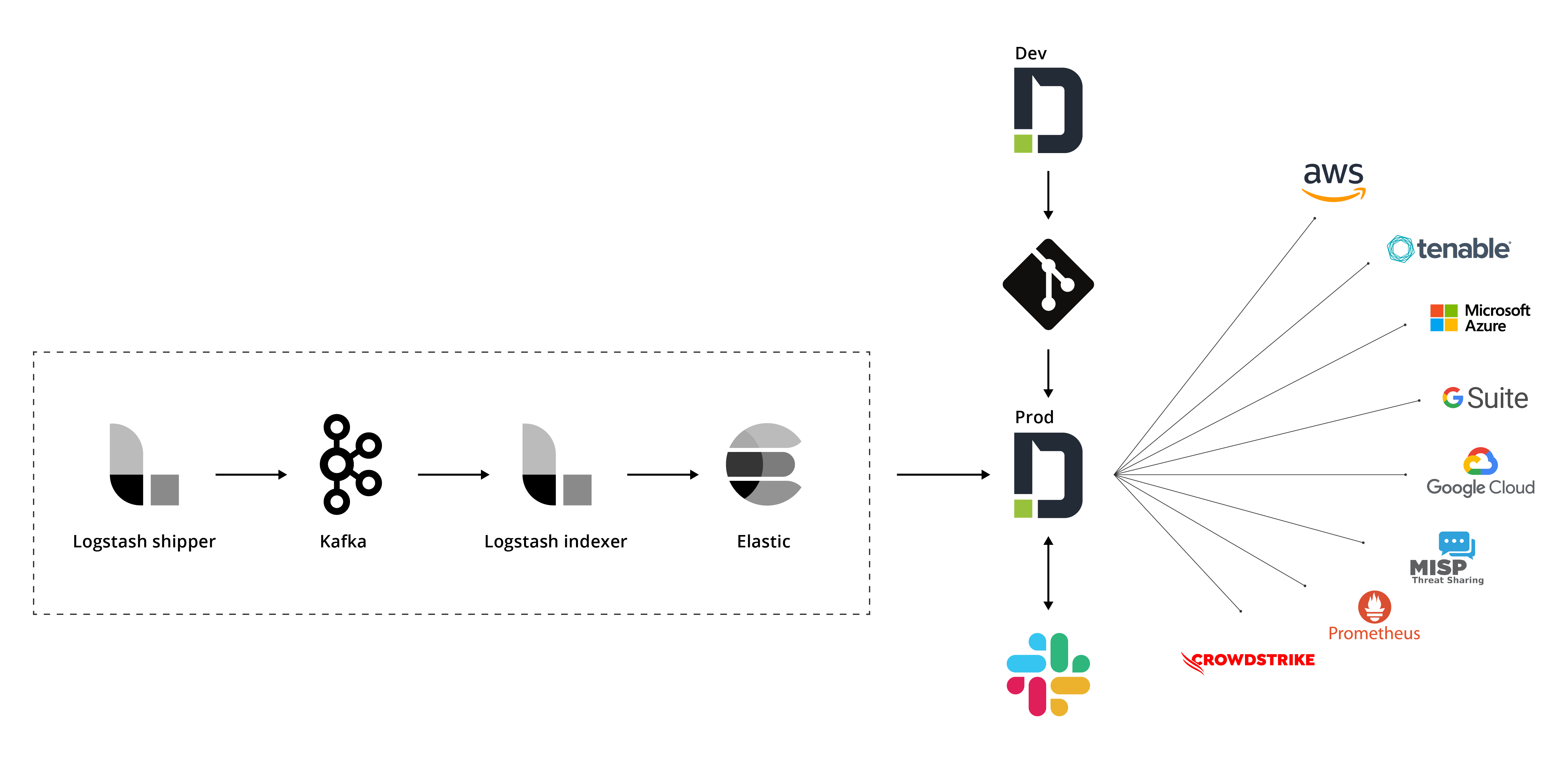
希望我们的旅程能够帮助其他团队重新思考他们的自动化SOC基础设施。
伸出手来,问问题,分享你的想法、担忧和想法LinkedIn.
我们在招人,看看空缺职位>
